
公共卫生学术热点追踪
Nat Med | 复旦大学李小英/陈颖等合作开发新的方法,优化2型糖尿病血糖控制
治疗2型糖尿病(T2D)的个性化胰岛素滴定和优化方案是一项资源密集型的医疗任务。
2023年9月14日,复旦大学李小英、陈颖及北京邮电大学王光宇共同通讯在Nature Medicine(IF=83)在线发表题为“Optimized glycemic control of type 2 diabetes with reinforcement learning: a proof-of-concept trial”的研究论文,该研究提出了一个基于模型的强化学习(RL)框架(称为RL-DITR),该框架通过分析患者模型相互作用的血糖状态奖励来学习最佳胰岛素方案。在开发阶段对T2D住院患者的管理进行评估时,与其他深度学习模型和标准临床方法相比,RL-DITR获得了更好的胰岛素滴定优化(平均绝对误差(MAE)为1.10±0.03 U)。
该研究对人工智能系统进行了从模拟到部署的逐步临床验证,通过盲法评价的定量(MAE为1.18±0.09 U)和定性指标,与初级和中级医生相比,人工智能系统在住院患者的血糖控制方面表现更好。此外,在16例T2D患者中进行了单臂、患者盲法、概念可行性验证试验。主要终点是试验期间平均每日毛细血管血糖的差异,从11.1(±3.6)降至8.6(±2.4)mmol L?1 (P < 0.01),达到预定终点。未发生严重低血糖或高血糖伴酮症发作。这些初步结果值得在更大、更多样化的临床研究中进一步调查。

2型糖尿病(T2D)是最普遍的慢性疾病之一,在世界范围内导致相当高的死亡率和社会负担1。血糖控制不良的T2D患者在疾病进展过程中需要胰岛素治疗。虽然良好的血糖控制可以显著降低住院糖尿病患者的糖尿病并发症和死亡率,但在有效和安全的范围内调整胰岛素剂量仍然具有挑战性和耗时。虽然专家们提出了一系列关于T2D患者合理使用胰岛素的临床指南,但胰岛素剂量滴定通常是根据临床指导和医生的经验来实现血糖目标,不能充分考虑现实世界中每个患者的可变性。一些治疗方案可能更适合某些患者,或者随着病情的发展,只适用于一段时间。因此,个性化、动态的胰岛素滴定对降低T2D患者血糖波动、预防T2D患者相关合并症和死亡率具有重要的临床意义。
人工智能(AI)方法已经成为帮助疾病诊断和管理的潜在强大工具8 - 10。现有的方法使用监督学习(SL),其中必须提供正确标签列表,用于疾病检测或发病率预测。然而,基于SL的方法假设专家的表现是最优的,由于人类代谢的复杂性和个体对药物的不同反应,这并不总是与现实世界的结果一致。
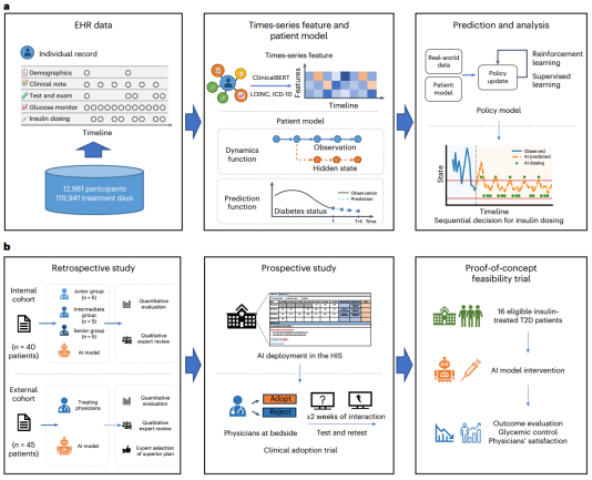
用于T2D患者胰岛素动态剂量滴定的AI系统从开发到部署的示意图(图源自Nature Medicine )
强化学习(RL)作为机器学习的一个子领域被提出,使智能体能够通过与动态环境的试错交互来学习有效的策略。RL可能为在各种医疗保健领域,特别是在长期患者护理的动态治疗方案(DTRs)中构建适应性政策提供有吸引力的解决方案。随着医疗记录数据的不断增加,RL已被用于各种临床场景的顺序医疗决策系统,包括败血症、冠心病和人工胰腺系统的血糖调节。虽然有几项研究使用无模型RL模型进行治疗建议,但这些方法通常面临挑战,例如在缺乏对环境的准确模拟时,样本效率和不安全政策的可能性。由于在复杂或长期的治疗方案中,安全性是首要考虑的问题,基于模型的强化学习可能提供模拟多种方案的潜力,从而在决策时提供可靠的前瞻性规划。尽管RL方法在基于患者结果的奖励设置优化治疗方案方面具有潜力,但由于临床实践中的潜在风险,其在治疗中的实际应用仍然有限。因此,将基于强化学习的方法从开发到采用纳入现实世界的临床工作流程需要进行全面的评估。
该研究构建了一个大型的T2D住院患者电子健康记录(EHRs)数据集,连续记录胰岛素使用方案和血糖反应至少7天。每个患者被表示为特征向量的时间序列,包括人口统计、血液生化测量、药物和胰岛素使用信息。基于连续住院患者电子病历数据,开发了一种基于RL的动态胰岛素滴定方案(RL-DITR),这种基于模型的强化学习方法通过与患者模型作为环境的迭代交互来学习最优策略。此外,作者引入了SL,通过使用临床医生的专业知识来保证安全状态,同时通过与动态环境的反复试验来优化结果,这可以模拟并潜在地增强医生在临床决策中的作用。该研究表明RL-DITR是一种潜在的工具,可以帮助临床医生,特别是初级医生和非内分泌专家,对住院T2D患者进行糖尿病管理。
(来源:iNature)
原文出处:Wang G, Liu X, Ying Z, Yang G, Chen Z, Liu Z, Zhang M, Yan H, Lu Y, Gao Y, Xue K, Li X, Chen Y. Optimized glycemic control of type 2 diabetes with reinforcement learning: a proof-of-concept trial. Nat Med. 2023 Sep 14. doi: 10.1038/s41591-023-02552-9. Epub ahead of print. PMID: 37710000.