
公共卫生学术热点追踪
Nature:首个能写综述论文的开源AI模型来了,大幅减少科研“幻觉”,堪比人类专家
科学进步取决于科研人员综合日益增多的文献资料的能力,面对科学文献的爆炸式增长,科研人员如何才能快速筛选、总结海量文献?大语言模型(LLM)是否能够在这方面为科研人员提供帮助?
在日常生活中,很多人会用到 ChatGPT、DeepSeek 等大语言模型来聊天、写邮件或生成答案,但当你问它一个专业、前沿的科学问题,它可能会给出看似合理但实际虚构的答案,甚至编造根本不存在的论文引用。这种“幻觉”问题在科研领域尤为致命,因为准确性是科学的生命线。
而现在,一项发表于 Nature 期刊的研究给出了解决方案——OpenScholar,这是一个专为科研打造的 AI 助手,不仅能准确回答复杂的科学问题,生成综述论文,还解决了 AI 喜欢胡编乱造的“幻觉”难题。

该研究来自华盛顿大学、艾伦人工智能研究所,于 2026 年 2 月 4 日在线发表于 Nature 期刊,论文题为:Synthesizing scientific literature with retrieval-augmented language models。
OpenScholar 是一个检索增强的语言模型(Retrieval-Augmented Language Model),它能够从 4500 万篇开放获取(Open Access)论文中智能检索相关段落,生成带引用的长篇综述论文(涵盖计算机科学、物理学、神经科学和生物医学领域),其引用准确率与人类专家相当,并在多项测试中超越了 GPT-4o 等主流大模型。更令人惊喜的是,研究团队全面开源了 OpenScholar,为科研社区提供了一个透明、可复现的工具。
OpenScholar 是什么?科研文献的“智能管家”
如果你是一名研究人员,需要写一篇关于“人工智能在医疗诊断中的应用”的综述论文。通常情况下,你需要花费数周甚至更长时间阅读上百篇相关研究论文,筛选关键信息,构思框架,最终完成综述论文的撰写、修改。
而 OpenScholar 就像一个高效的智能助手,只需输入问题,它就能在几分钟内合成一份结构清晰、引用准确的综述论文。
OpenScholar 的核心创新在于其全开放、可检索增强的架构。它不依赖“黑箱” API,而是构建了一个包含 4500 万篇开放获取论文的专用数据存储(OpenScholar DataStore,OSDS),并配备了训练过的检索器和生成模型。该系统通过以下步骤工作:
1、检索阶段:从多个来源(例如学术数据库和网络搜索)智能抓取相关论文段落。
2、生成阶段:语言模型基于检索到的内容起草答案,并标记引用。
3、自反馈循环:模型会自我审查初稿,提出改进意见(例如“需要补充更多实验数据”),并迭代优化答案,确保事实性和覆盖范围。
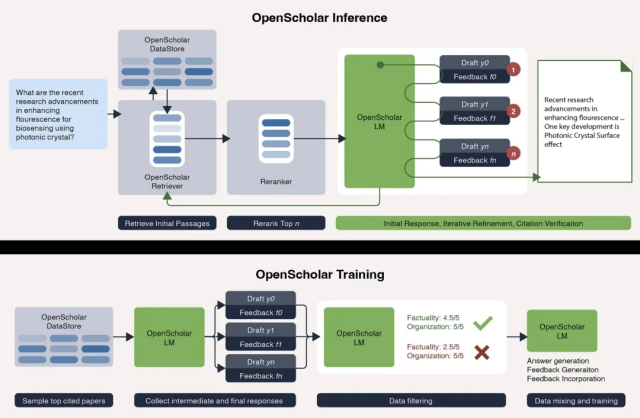
OpenScholar 推理(上)和训练流程(下)
这张图清晰展示了 OpenScholar 的工作流程:从输入查询到最终输出,每一步都注重证据支撑。这种设计直接针对了当前 AI 在科学领域应用的痛点——例如,该研究显示,当要求 GPT-4o 引用计算机科学或生物医学等领域的近期文献时,其在 78%-90% 的情况下编造了引用,而 OpenScholar 的引用准确性堪比人类专家。
如何评估 AI 的“科研能力”?ScholarQABench 基准登场
要判断一个 AI 系统是否可靠,需要严格的测试标准。为此,研究团队开发了 ScholarQABench,这是首个大规模、多领域的科学文献合成基准。它包含近 3000 个由专家编写的问题,覆盖计算机科学、物理、神经科学和生物医学等领域,要求模型生成长篇、多论文支持的答案。
与以往只关注选择题或短答案的基准不同,ScholarQABench 引入了多维评估协议,包括自动指标(例如引用准确性)和人类专家基于量表的评分(覆盖范围、连贯性、写作质量等)。例如,在“计算机科学”部分中,专家会列出答案必须包含的关键要点,AI 的回答需要满足这些“评分标准”才能得分。
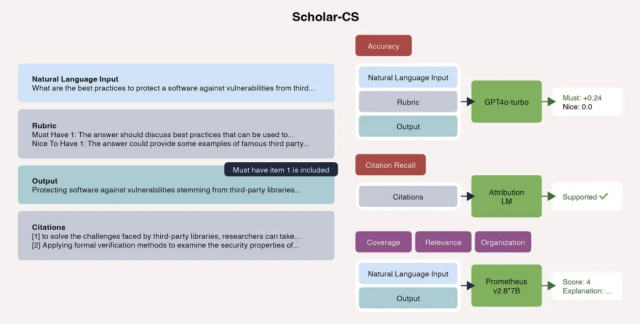
上图是一个评估示例:问题、评分标准和 AI 输出的对比。这种设计确保了评估的客观性,避免了 AI “刷分”的可能。
实验结果:小模型大能量,OpenScholar 全面领先
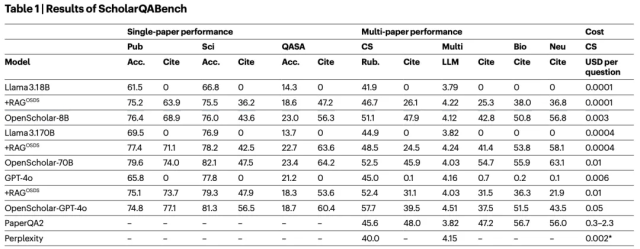
OpenScholar 在 ScholarQABench 上的测试结果令人印象深刻。尽管 OpenScholar 的核心模型参数量仅为 80 亿(远小于 GPT-4o 的规模),但它在多项任务中表现优异:
- 正确率提升:在需要多论文合成的任务中,OpenScholar-8B 比 GPT-4o 高出 6.1%,比 PaperQA2 高出5.5%。
- 引用准确性:OpenScholar 的引用 F1 分数达到 47.9%,而 GPT-4o 几乎为 0。
- 成本效益:使用高效的检索管道,OpenScholar-8B 的成本比基于 GPT-4o 的商业系统更低。
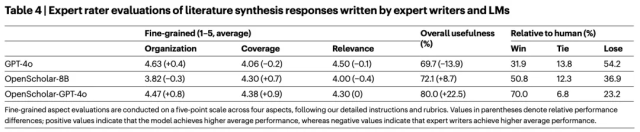
更引人注目的是人类评估结果:16 位人类专家在盲测中比较了 AI 回答和人类专家撰写的答案。结果显示,人类专家在 50.8% 和 70.0% 的情况下选择了 OpenScholar-8B 和 OpenScholar-GPT-4o 的回答,而 GPT-4o 的这一比例仅为 31.9%,人类专家认为,OpenScholar 的回答更全面、信息深度更大,而这正是撰写综述论文所需的关键能力。
AI,正在改变科研范式
OpenScholar 的推出标志着 AI 在科学领域的应用迈出重要一步。它不仅是工具的创新,更体现了开放科学的精神——通过可复现的系统,降低科研门槛。对于忙碌的科学家和学生来说,这类 AI 助手有望将文献回顾从“苦役”变为高效探索。
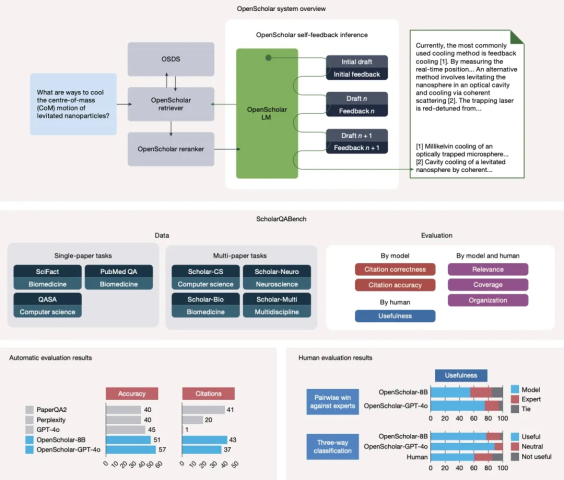
OpenScholar、ScholarQABench 概述及评估结果
未来,随着多模态学习和用户反馈的整合,OpenScholar 可能会变得更智能,从而成为科研人员的真正“协作者”,让科研工作更聚焦于创新而非信息筛选。
(来源:生物世界)
原文出处:Asai A, He J, Shao R, Shi W, Singh A, Chang JC, Lo K, Soldaini L, Feldman S, D'Arcy M, Wadden D, Latzke M, Sparks J, Hwang JD, Kishore V, Tian M, Ji P, Liu S, Tong H, Wu B, Xiong Y, Zettlemoyer L, Neubig G, Weld DS, Downey D, Yih WT, Koh PW, Hajishirzi H. Synthesizing scientific literature with retrieval-augmented language models. Nature. 2026 Feb 4. doi: 10.1038/s41586-025-10072-4. Epub ahead of print. PMID: 41639446.